Identifying biases in legal data: An algorithmic fairness perspective
By Chloe Chen, based on work by Jackson Sargent and Melanie Weber.
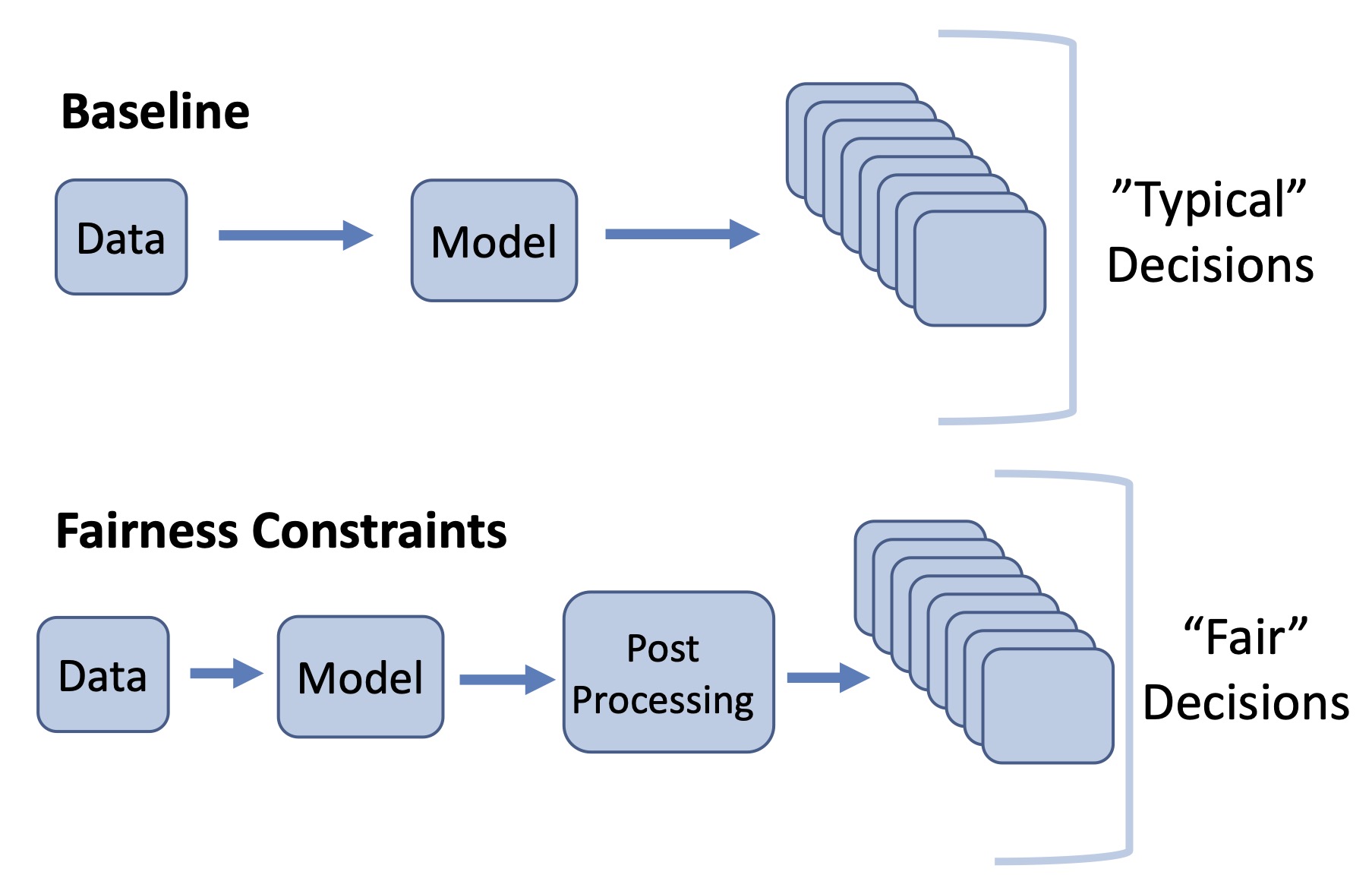
The Process
We typically find two types of biases in legal data: representation biases, where certain groups are over- or underrepresented in a data set, and sentencing disparities, where the outcome of legal proceedings for similar cases varies across different groups.
In this study, an efficient and versatile process is developed to identify and measure legal biases in large-scale legal data. To account for sentencing disparities, the process compares two regression models-- one baseline model trained on real-world data to represent a “typical” judge, and a second model trained with fairness constraints to represent a “fair” judge.
The “fair” judge is trained to adhere to one of three concepts of fairness:
- Demographic parity, which requires that the outcome is independent of the protected characteristic;
- Equalized odds, which equalizes both true positive and false positive ratings across demographic groups; and
- Equal opportunity, which equalizes only true positive rates across demographic groups.
Additionally, to account for representation bias, data is balanced via random subsampling. Essentially, to achieve a more equal split between two binary outcomes, an appropriately sized subset is sampled from the outcome with more data points.
The Experiment
To see this method in action, these trained models were applied to two crime types (narcotics and theft). This experiment was run four times using two different regression models and two different measured outcomes (“free bond”, which represents whether bail without upfront payment was granted, and “charge reduction”, which represents whether charge was reduced upon appeal.). The differences were measured across two demographic binaries (white/black and male/female).
The fairness of the outcomes are measured with the following metrics, formally defined for binary output Ŷ (such as, whether or not the charge was reduced) conditioned on a protected attribute A:
- Demographic parity difference ΔDP := |P[Ŷ = 1 | A = 0] - P[Ŷ = 1 | A = 1]|
- True positive difference ΔTP := |P[Ŷ = 1 | A = 0, Y = 1] - P[Ŷ = 1 | A = 1, Y = 1]|
- False positive difference ΔFP := |P[Ŷ = 1 | A = 0, Y = 0] - P[Ŷ = 1 | A = 1, Y = 0]|
As an example, let’s take a look at the results of this method using logistic regression as the training method and free bond as the measured outcome:
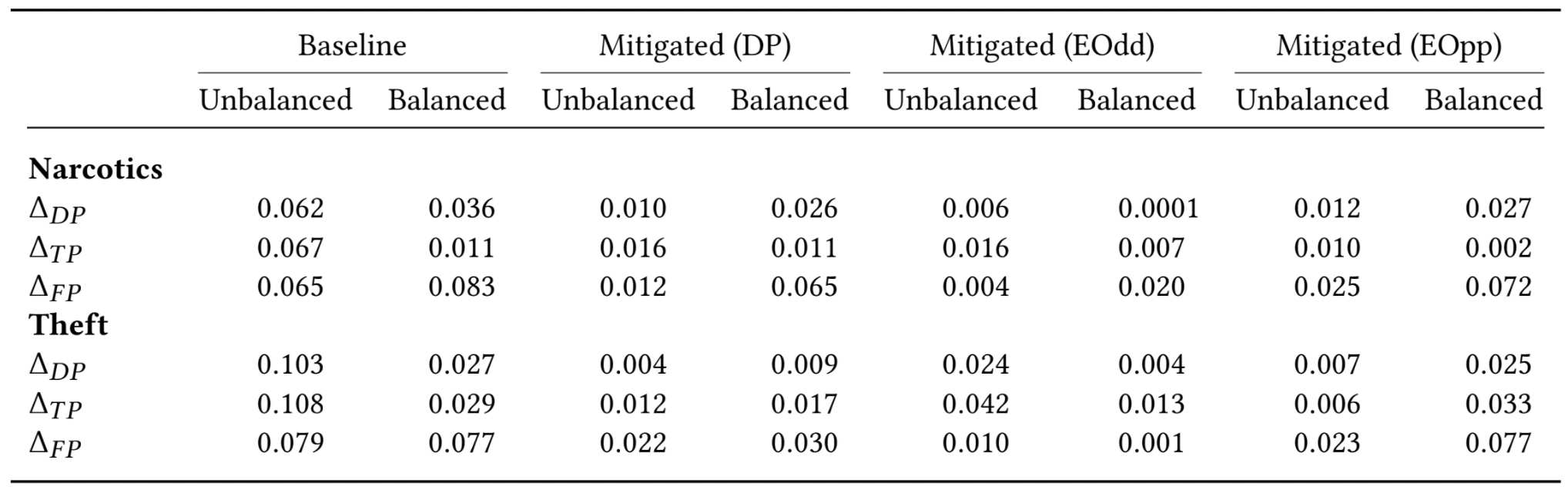
As the figure above shows, all measures of fairness are significantly improved in each of the “fair” judges, compared to the baseline “typical” judge, as well as in the balanced cases compared to the unbalanced cases.
Why It Matters
This approach can be used to identify biases in the legal system and suggest areas for mitigating disparities. In our case studies, we see that equalized odds with balancing provided the best mitigation across the four case studies. This suggests that our current judicial model could benefit from sentencing guidelines that equalize the rate of positive and negative outcomes across demographic groups. One of the primary objectives of sentencing guidelines is to reduce the sanctioning of innocent defendants; thus, imposing fairness constraints that equalize false positive rates across demographic groups is a promising avenue for mitigating sentencing disparities.
More generally, this process offers a new way to identify and measure legal biases. Most current literature analyzes disparities (eg. sentencing disparities) by analyzing correlations between the characteristics of the defendant – and sometimes the judge – with the case outcome. This study is, as far as we know, the first to evaluate biases in legal data from an algorithmic fairness perspective, and we hope it can shed some light on suitable notions of fairness for legal proceedings and on pipelines for systematically analyzing bias in large-scale legal data.
Additionally, unlike most previous studies of this kind, this study focuses not primarily on sentencing disparities in the final case outcome, but rather on other aspects of the legal process such as whether bail without upfront payment was granted (free bail) and whether charge was reduced upon appeal (charge reduction). This opens the door for future studies to look at the implications of fairness constraints on metrics such as the likelihood of repeated offenses (for charge reduction) or failure to appear in court (free bonds).